BERT(Bidirectional Encoder Representations from Transformers)是 Google 於 2018 年發表的自然語言處理模型,它徹底改變了機器理解人類語言的方式。BERT 的核心突破在於「雙向理解」——它能同時參考一個詞前後的所有語境,而不是只從左讀到右。在 2026 年的 AI 搜尋時代,當您使用 ChatGPT、Perplexity、Google AI Overviews 提出複雜問題時,背後的語意理解、上下文判斷、實體辨識大多源自 BERT 與其衍生模型(RoBERTa、ALBERT、DeBERTa 等)所建立的技術基礎。這篇文章適合 SEO 從業者、行銷企劃、產品經理、研究 AI 應用的工程師,以及想了解 AI 搜尋如何運作的企業主閱讀。
BERT 是什麼?一個能讀懂上下文的語言模型
BERT 全名為 Bidirectional Encoder Representations from Transformers(雙向編碼器表示的變換器),是 Google AI Language 團隊於 2018 年 10 月發表的預訓練語言模型。它的最大特色是「雙向」——能同時從一個詞的前後文判斷它的真正含義,這是過去單向模型(如 GPT-1、ELMo)做不到的事。
BERT 不是「會說話的 AI」,而是「能精準理解語言的引擎」。它本身不生成內容,而是幫機器讀懂一段文字真正在說什麼。
用一個例子理解 BERT 的雙向理解
請看以下兩個句子,「銀行」這個詞代表的意思完全不同:
- 句子 A:「我去銀行領錢。」(金融機構)
- 句子 B:「他坐在河銀行邊釣魚。」(河岸,bank 的另一個意思)
傳統的單向模型(從左讀到右),在讀到「銀行」這個詞時,可能還無法判斷後面會出現什麼;但 BERT 會同時考慮整句話的前後文,因此能準確判斷「銀行」在句子 A 中是金融機構、在句子 B 中是河岸。這種「上下文敏感的詞義理解」,就是 BERT 改變 NLP 的關鍵。
BERT 不會「生成內容」,它只負責「理解」
許多人會把 BERT 和 ChatGPT、GPT-4 混淆,但它們的設計目的不同。BERT 是編碼器(Encoder)架構,專注於「理解輸入」;GPT 系列是解碼器(Decoder)架構,專注於「產生輸出」。在現代 AI 系統中,兩者經常搭配使用——BERT 負責讀懂使用者的問題,GPT 負責生成自然的回答。
BERT 為什麼重要?它解決了哪些 NLP 難題?
在 BERT 出現之前,NLP 模型多半針對單一任務從頭訓練——做情感分析就訓練一個情感模型,做問答系統再訓練另一個。每個任務都需要大量標註資料,訓練成本高、效果也參差不齊。
BERT 的革命性貢獻是「預訓練 + 微調」這個典範——先讓模型在海量文本上學會「通用的語言能力」,再用少量資料微調到特定任務。
BERT 解決的三大難題
BERT 在 GLUE 基準測試上的突破性表現
2018 年 BERT 在 GLUE(General Language Understanding Evaluation)基準測試上,一舉刷新 11 項 NLP 任務的最佳紀錄,部分任務的表現甚至超越人類平均水準。這也是為什麼 BERT 發表後,幾乎所有後續 NLP 模型都以 BERT 為基礎進行改良。
BERT 的核心技術:雙向、預訓練、Transformer
要理解 BERT 為什麼強大,需要先認識它建立在三個關鍵技術之上:Transformer 架構、雙向編碼、大規模預訓練。
1. Transformer 架構:讓 BERT 能平行處理
BERT 採用 Google 於 2017 年發表的 Transformer 架構,核心是自注意力機制(Self-Attention)。這個機制讓模型在處理一個詞時,能直接「看到」整句話中所有其他詞,而不像傳統 RNN、LSTM 需要逐字逐句處理。
Transformer 的優勢是平行運算——傳統 RNN 必須等前一個字處理完才能處理下一個,Transformer 可以一次性處理整個句子,訓練速度大幅提升。
2. 雙向編碼:同時看前後文
傳統語言模型只能單向預測(從左到右,或從右到左)。BERT 則使用遮罩語言模型(Masked Language Model),讓模型同時參考一個詞的前後文,真正達到「雙向」理解。
3. 大規模預訓練:站在巨人肩膀上
BERT 在維基百科(25 億字)+ BookCorpus(8 億字)上進行預訓練。這個過程不需要人工標註,模型透過「自我監督」自動學習語言規則。預訓練完成後,任何下游任務只需用少量標註資料微調,就能達到極好的效果。
BERT 兩個官方版本:Base 與 Large
| 項目 | BERT-Base | BERT-Large |
|---|---|---|
| Transformer 層數 | 12 層 | 24 層 |
| 隱藏層維度 | 768 | 1024 |
| 注意力頭數 | 12 個 | 16 個 |
| 參數量 | 1.1 億 | 3.4 億 |
| 適用場景 | 一般任務、資源有限 | 追求極致效能 |
BERT 的兩大預訓練任務:MLM 與 NSP
BERT 的預訓練透過兩個任務同時進行——遮罩語言模型(MLM)與下一句預測(NSP)。這兩個任務分別培養模型對「詞」與「句子關係」的理解能力。
隨機遮蓋輸入句子中 15% 的詞,讓模型預測被遮蓋的詞是什麼。其中 80% 用 [MASK] 取代、10% 用隨機詞取代、10% 保留原詞——這種設計避免模型只在預訓練時看到 [MASK],微調階段反而無法泛化。
給定兩個句子 A 和 B,讓模型判斷 B 是否為 A 的下一句。50% 的訓練資料使用真實連續的句子對、50% 使用隨機拼接的句子對。這個任務培養 BERT 理解「句子間關係」的能力,對問答、自然語言推論等任務特別重要。
BERT 的實際應用場景
BERT 不是只在學術界存在的模型,它已被大量整合到實際產品中。以下是 BERT 在 2026 年仍廣泛應用的七大實務場景:
-
搜尋引擎查詢理解
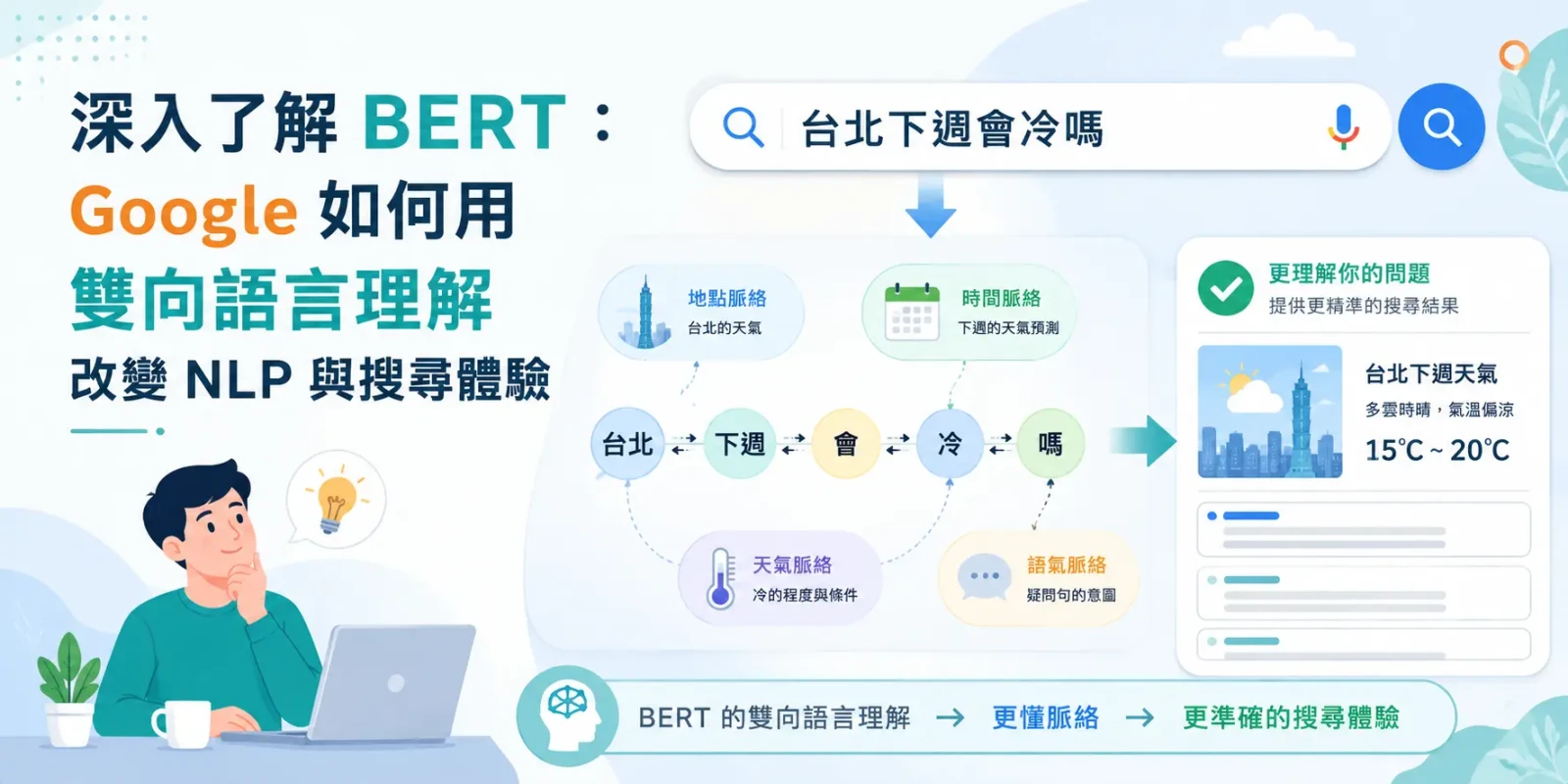
Google 自 2019 年起將 BERT 導入搜尋演算法,協助理解使用者的查詢意圖,尤其是含介系詞、否定詞或口語化的長尾查詢。
查詢「2026 年從台灣去日本要簽證嗎」——BERT 能理解「2026 年」、「從台灣去」、「簽證」之間的關係,而不是單純做關鍵字配對。
-
文本分類(情感分析、垃圾郵件偵測)
BERT 可微調用於各種文本分類任務,如商品評論的情感正負面判斷、垃圾郵件過濾、新聞主題分類等。
電商平台用 BERT 自動分析 PChome、蝦皮的商品評論情感,輔助商家判斷客戶滿意度。
-
問答系統(QA System)
BERT 可從一段文章中找出問題的答案位置(Extractive QA)。SQuAD 基準測試上,BERT 的表現一度超越人類水準。
客服 FAQ 系統中,使用者輸入「退貨要幾天」,BERT 從公司政策文件中精準擷取「需在 7 天內申請退貨」這段答案。
-
命名實體識別(NER)
從文本中識別人名、地名、公司名、日期、金額等實體。台灣金融業常用此技術自動處理合約、新聞抓取。
輸入「台積電於 2026 年 3 月在熊本宣布投資 800 億日圓」→ BERT 識別公司:台積電、日期:2026 年 3 月、地點:熊本、金額:800 億日圓。
-
語意搜尋與向量檢索
將文章用 BERT 編碼為向量,可進行語意相似度搜尋——即使查詢用詞與文章不同,只要意思相近,也能被檢索到。
查詢「便宜的筆電」→ 即使文章寫「平價筆記型電腦」,也能被找到,因為 BERT 理解兩者語意相近。
-
機器翻譯品質提升
雖然主流翻譯模型多採用 Seq2Seq,但 BERT 的雙向理解能力可協助處理原文歧義,提升翻譯品質。
英文「She read the book」中的 read 究竟是現在式還是過去式,BERT 能根據前後文判斷,協助翻譯系統選擇正確時態。
-
自然語言推論(NLI)
判斷兩段文字之間的邏輯關係——蘊含(Entailment)、矛盾(Contradiction)、中立(Neutral),對法律、醫療文件審查很有用。
前提「所有員工每年都有 14 天特休」+ 假設「兼職員工也有特休」→ BERT 判斷為「中立」(原文未明確說明)。
程式碼範例:用 Hugging Face 載入 BERT 做情感分析
以下是一個用 Python 與 transformers 套件呼叫預訓練 BERT 模型的簡單範例:
from transformers import pipeline
# 載入預訓練的 BERT 情感分析模型
classifier = pipeline(
"sentiment-analysis",
model="bert-base-uncased"
)
# 進行情感分析
result = classifier("BERT is an amazing model for NLP tasks!")
print(result)
# 輸出: [{'label': 'POSITIVE', 'score': 0.9998}]
BERT 對 SEO 與 AI 搜尋的影響
BERT 對 SEO 產業的影響可說是劃時代的。Google 在 2019 年 10 月正式宣布將 BERT 導入英文搜尋演算法,2019 年 12 月擴展到包含繁體中文在內的 70 種語言。這意味著關鍵字堆砌、生硬填充的內容策略徹底失效。
BERT 之後的 SEO 寫作關鍵變化
- 內容必須回答完整的使用者問題,不是堆砌關鍵字
- 段落要有清楚的上下文連貫,Google 能理解前後段的關係
- 長尾、口語化、含介系詞與否定詞的查詢開始能被精準匹配
- 同義詞、近義詞、語意相關詞同樣有效——不必每段都重複主關鍵字
- 使用者意圖(Intent)比關鍵字密度更重要
AEO(Answer Engine Optimization)與 BERT 的關係
AEO(答案引擎優化)是 2024 年後興起的概念,目標是讓內容被 ChatGPT、Perplexity、Google AI Overviews、Claude 等 AI 搜尋引擎引用為答案來源。AEO 的技術基礎正是建立在 BERT 與後續大型語言模型對「語意理解」的能力上。
SEO 是讓網頁出現在搜尋結果列表中;AEO 是讓內容成為 AI 回答中的引用來源。前者比排名,後者比可信度與結構清晰度。
實務上 AEO 與 BERT 友善的內容,通常具備以下五個特徵:
- 明確的問題式小標 H2、H3 直接寫成使用者會問的問題(如本文小標「BERT 是什麼?」「BERT 為什麼重要?」),讓 AI 能精準擷取答案區塊。
- 前 2 句就給結論 每個段落第一句話直接回答問題,後面再展開細節。AI 摘要時通常擷取前幾句作為答案。
- 結構化資料(Schema) 使用 FAQPage、Article、HowTo 等 JSON-LD Schema 標記,讓 AI 更容易解析內容結構。
- 具體數據與實例 引用具體數字(「GLUE 11 項任務刷新紀錄」、「BERT-Base 1.1 億參數」)比抽象說明更容易被 AI 引用。
- 作者權威(E-E-A-T) 標示作者、發布日期、引用權威來源——AI 在判斷可信度時,會優先選擇有清楚作者署名的內容。
BERT 衍生模型比較:RoBERTa、ALBERT、DistilBERT
BERT 發表後,學界與業界提出了大量改良版本,各自針對效能、模型大小、訓練速度等面向優化。以下是最重要的四個衍生模型比較:
| 模型 | 提出時間 | 核心改進 | 適用情境 |
|---|---|---|---|
| RoBERTa | 2019(Facebook) | 移除 NSP、更大批次、更多資料、動態遮罩 | 追求極致效能、資源充足 |
| ALBERT | 2019(Google) | 參數共享、因式分解,大幅減少參數量 | 記憶體受限、需部署到邊緣裝置 |
| DistilBERT | 2019(Hugging Face) | 知識蒸餾,保留 97% 效能但縮小 40% | 需快速推論、行動裝置應用 |
| DeBERTa | 2020(Microsoft) | 解耦注意力、增強遮罩解碼 | 超越人類水準的高精度任務 |
| ELECTRA | 2020(Google) | 替換符偵測取代 MLM,訓練效率更高 | 訓練資源有限、想自己預訓練 |
中文 BERT 模型選擇
針對繁體中文應用,推薦以下幾個經實務驗證的預訓練模型:
bert-base-chinese:Google 官方中文 BERT,基礎首選hfl/chinese-bert-wwm-ext:哈工大訊飛實驗室的全詞遮罩版本,中文效果優於官方版ckiplab/bert-base-chinese:中研院 CKIP Lab 釋出,針對繁體中文優化hfl/chinese-roberta-wwm-ext:RoBERTa 中文版,當前繁中 NLP 任務的主流選擇
使用 BERT 常見錯誤與迷思
即使 BERT 已發表超過 7 年,許多企業導入 NLP 應用時仍常踩到以下六個典型錯誤:
- 以為 BERT 能「生成內容」 BERT 是編碼器,只負責理解,不負責生成。如果需要寫文章、寫摘要、聊天對話,應使用 GPT、T5、BART 等生成模型,或現代的 LLM(如 Claude、ChatGPT)。改善方式:明確區分「理解任務」(用 BERT)與「生成任務」(用 GPT 系列)。
-
直接用英文 BERT 處理中文資料
bert-base-uncased是英文模型,中文表現會極差。改善方式:使用bert-base-chinese或哈工大、CKIP Lab 的繁中專用版本。 - 微調資料量過少導致過擬合 BERT 模型參數超過 1 億,若用幾十筆資料微調,模型會記住訓練樣本卻無法泛化。改善方式:至少準備 1000 筆以上標註資料、使用 dropout、early stopping、學習率衰減等正則化手段。
- 忽略最大長度限制 512 BERT 預設輸入長度上限為 512 個 token,長文件直接丟進去會被截斷。改善方式:使用分段策略(sliding window)、改用 Longformer / BigBird 等長文件模型,或先做摘要再丟入 BERT。
- 在生產環境直接部署 BERT-Large BERT-Large 推論延遲高、記憶體需求大,直接部署到 API 服務常造成成本爆炸。改善方式:正式上線優先選 DistilBERT、ALBERT 等輕量化模型,或用 ONNX、TensorRT 進行推論加速。
- 期望 BERT 解決所有 NLP 問題 BERT 雖強,但對需要長期記憶、多輪對話、邏輯推理的任務不見得最適合。改善方式:依任務性質選對工具——分類用 BERT、生成用 GPT、長文件用 Longformer、多輪對話用 LLM。
結論:BERT 為什麼是 NLP 的里程碑?
BERT 之所以被稱為 NLP 領域的里程碑,在於它建立了三個改變產業的典範——預訓練 + 微調的開發流程、Transformer 編碼器架構的主流地位、雙向語意理解的標準。今天我們所熟悉的 ChatGPT、Claude、Perplexity、Google AI Overviews 等 AI 應用,技術根源都能追溯到 2017 年的 Transformer 與 2018 年的 BERT。
如果您正在評估是否要把 BERT 或衍生模型導入產品,可以先從以下五個問題自我檢查:
- 您的任務是「理解輸入」還是「生成輸出」?理解任務適合 BERT 系列。
- 您處理的是中文還是英文?要選對應語言的預訓練模型。
- 您有多少標註資料?太少資料無法穩定微調 BERT,需先擴增資料或考慮 few-shot 方法。
- 您的推論延遲與成本預算?生產環境通常需要輕量化版本(DistilBERT、ALBERT)。
- 您的輸入長度通常多長?超過 512 token 需要分段或選 Longformer。
常見問答 FAQ
BERT 和 ChatGPT 有什麼差別?
BERT 對 SEO 有什麼具體影響?我該如何因應?
學習 BERT 需要哪些前置知識?
BERT 處理繁體中文效果好嗎?該用哪個版本?
bert-base-chinese 是以簡體中文為主訓練的,可處理繁體但有些字詞理解較弱。推薦以下選擇:1. 中研院 CKIP Lab——ckiplab/bert-base-chinese 與 ckiplab/albert-base-chinese,針對繁體中文新聞、學術文獻優化,適合台灣本地應用。2. 哈工大訊飛聯合實驗室——hfl/chinese-bert-wwm-ext 與 hfl/chinese-roberta-wwm-ext 使用全詞遮罩(Whole Word Masking)技術,對中文語意理解優於原版,雖以簡體訓練但繁體效果也不錯。3. 台達電子研究院——也釋出過繁體中文預訓練模型,適合金融、客服場景。實務建議:先用 hfl/chinese-roberta-wwm-ext 試水溫,效果不夠再考慮 CKIP Lab 版本或自行針對台灣語料微調。台灣中小企業若想做客服自動回覆、商品評論分析,這些開源模型完全夠用,不需從頭預訓練。
BERT 在 2026 年還重要嗎?會不會被大型語言模型取代?
沒有機器學習基礎也能用 BERT 嗎?
transformers 套件,僅需 5 行 Python 程式碼就能呼叫預訓練模型做情感分析、文本分類、問答等任務。適合入門者的路徑:1. 先用現成 Pipeline——Hugging Face 提供 pipeline("sentiment-analysis") 之類的快速介面,完全不需懂模型內部。2. 嘗試 No-code 工具——AutoML 平台如 Hugging Face AutoTrain、Google Vertex AI 提供無程式碼介面,上傳資料就能訓練自訂 BERT 模型。3. 用 Colab 學習——Google Colab 提供免費 GPU,搭配網路上大量 BERT 教學筆記本,可邊做邊學。注意事項:若您需要進階客製化(自訂預訓練、改架構、處理超長文件、優化推論速度),仍需深入學習深度學習與 PyTorch/TensorFlow。但對大多數企業應用(客服分類、評論分析、合約抽取等),現成模型 + 簡單微調已綽綽有餘。台灣中小企業 IT 預算有限的情況下,優先選擇 Hugging Face 生態系是最務實的路徑。