
技術 SEO 實戰指南:從 Canonical 重複內容到 JavaScript 渲染的完美攻略
你是否曾遇過這種令人崩潰的情況:網站設計得美輪美奐,但在 Google Search Console (GSC) 中卻滿江紅?明明內容很豐富,爬蟲抓到的卻是一片空白;或者明明是同一件商品,卻因為顏色參數不同,被 Google 判定為數百個「重複頁面」而遭到降權。
這不是內容品質的問題,這是溝通語言的問題。這就是所謂的 技術債 (Technical Debt) —— 你的網站架構正在拖累你的行銷成效。
在前一篇《SEO 基礎開發 (上)》中,我們處理了 301 重定向與 SSL 的地基;而在這篇進階指南中,我們要教會你的網站「說 Google 聽得懂的母語」。我們將深入探討 結構化資料、Canonical 標籤 以及現代前端框架最頭痛的 JavaScript SEO,確保你的技術實力能完美轉化為搜尋排名。
本文重點摘要 (Key Takeaways):
- 重複內容剋星: 學會使用 Canonical Tag (標準網址標記),精準告訴 Google 哪個頁面才是「本尊」,避免權重被參數網址稀釋,集中排名火力。
- 搶佔黃金版位: 利用 JSON-LD 格式部署 Schema,讓網站在搜尋結果中顯示星級、FAQ 與價格,大幅提升點擊率 (CTR)。
- 前端開發避坑: 解析 JavaScript 渲染 (CSR) 為何會導致收錄失敗,以及如何透過 SSR 或混合渲染 (Hydration) 解決爬蟲「看得到吃不到」的窘境。
- 國際化佈局: 正確設定 Hreflang 標籤,讓多語系網站在全球市場精準落地,不再發生語系錯亂,鎖定正確的目標受眾。
解決重複內容危機:Canonical Tag (標準網址) 的正確用法
在 Google 的眼中,每一條獨一無二的網址 (URL) 都代表一個獨立的頁面。這聽起來很合理,但對大型網站來說,這往往是災難的開始。
重複內容 (Duplicate Content) 是 SEO 排名最大的隱形殺手之一。當多個網址指向相同的內容時,搜尋引擎會感到困惑,不知道該將權重給誰。最糟糕的情況是,Google 會「自行決定」哪一頁是主頁,而那個選擇通常不是你想要的(例如選到了帶有亂碼參數的網址),最終導致所有頁面的排名集體下滑。
這時,你需要 Canonical Tag (標準網址標記) 來扮演交通警察的角色,強制指定唯一的標準版本。
為什麼你的網站會有「分身」? (電商與追蹤碼災難)
很多開發者認為:「我的內容都是原創的,哪來的重複?」事實上,技術架構本身就可能產生大量分身。常見的「SEO 稀釋陷阱」包括:
- URL 參數 (Parameters): 商品頁面因排序或篩選產生變化,如 /product?color=blue 或 /product?sort=price_desc。內容 99% 相同,但網址不同。
- 行銷追蹤碼 (Tracking Codes): Facebook 廣告帶來的 ?utm_source=fb,或是電子報連結的 ?ref=newsletter,在 Google 眼中這是一個全新的網址。
- 首頁分身: https://example.com、https://example.com/index.html 與 http://example.com 其實是三個不同的網址,若未統一,權重會被拆成三份。
- 列印版頁面: 某些網站會自動生成「列印友善版」頁面,內容完全相同,這也是常見的重複內容來源。
若不處理,這些分身會消耗你的 爬蟲預算 (Crawl Budget),讓 Google 把寶貴的抓取額度浪費在無意義的參數頁,而非重要的新文章。
設定 Canonical 的黃金法則
解決方案很簡單:在所有「分身頁面」的 <head> 區塊中,加入指向「本尊頁面」的標籤。
<link rel="canonical" href="https://example.com/product/t-shirt" />但在實作時,請務必遵守以下三大鐵律,否則可能產生反效果:
永遠使用包含 https:// 的完整網址。不要使用相對路徑 (/product/...),以免爬蟲判斷錯誤,導致指向不存在的層級或協議。
即使是「本尊頁面」自己,也要指向自己。這是一個防禦性策略,能預防當別人用錯誤的參數連結連到你的主頁面時,Google 依然能識別出這就是原始標準版。
Canonical 不僅限於站內。如果你將文章授權轉載到其他平台,請要求對方在原始碼中設定 Canonical 指回你的官網。這是將外部流量權重「歸還」給你的最強手段。
常見錯誤警示: 千萬不要將 Canonical 指向一個 404 (不存在) 或 301 (已轉址) 的頁面,這會讓爬蟲陷入死循環,嚴重傷害 SEO。

讓搜尋結果更吸睛:Schema 結構化資料與 JSON-LD
排名第一就夠了嗎?如果你的標題平淡無奇,使用者可能還是會點擊排名第二、但帶有五顆星評價或 FAQ 列表的競爭對手。這就是 結構化資料 (Structured Data) 的戰場。
結構化資料是一組標準化的標記語言(Schema.org),它的作用不是改變網頁的外觀,而是用搜尋引擎看得懂的語言,標記出網頁中的「實體」。例如:告訴 Google 這串數字是「價格」,那串文字是「食譜烹飪時間」。
當 Google 讀懂這些資訊後,就能在搜尋結果頁 (SERP) 呈現 複合式搜尋結果 (Rich Results)。這能顯著提升你的 CTR (點擊率),有時甚至能達到 30% 的增長,讓你在不提升排名的情況下獲得更多流量。
為什麼 JSON-LD 是 Google 的首選格式?
早期開發者習慣使用 Microdata,將標記直接寫在 HTML 標籤內(如 <div itemprop="name">)。這導致程式碼雜亂且維護困難,只要前端改個排版或 class 名稱,SEO 設定可能就跟著壞了。
現在,Google 強烈建議使用 JSON-LD 格式。
JSON-LD 是一段獨立的 JavaScript 代碼,通常放在 <head> 區塊中。它的好處是 內容與表現分離:你可以在不影響網頁視覺設計的情況下,任意修改給爬蟲看的數據。這對現代的前端開發流程來說,是更乾淨、更不易出錯的選擇。
實戰演練:部署產品 Schema (Product)
想讓你的商品在搜尋結果中直接顯示「$990」和「⭐⭐⭐⭐⭐」嗎?你需要在產品頁面植入以下代碼。請注意,除了產品 (Product),麵包屑 (BreadcrumbList) 與 問答頁 (FAQPage) 也是電商必備的標記組合。
請參考這段標準的 JSON-LD 範例:
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "人體工學辦公椅",
"image": [
"https://example.com/photos/1x1/photo.jpg",
"https://example.com/photos/16x9/photo.jpg"
],
"description": "這款椅子專為長時間工作設計,具備 3D 腰靠支撐。",
"sku": "0446310786",
"brand": {
"@type": "Brand",
"name": "ErgoLife"
},
"review": {
"@type": "Review",
"reviewRating": {
"@type": "Rating",
"ratingValue": "4",
"bestRating": "5"
},
"author": {
"@type": "Person",
"name": "王大明"
}
},
"offers": {
"@type": "Offer",
"url": "https://example.com/product/chair",
"priceCurrency": "TWD",
"price": "5990",
"availability": "https://schema.org/InStock",
"priceValidUntil": "2024-12-31"
}
}
</script>⚠️ 開發者注意:
- 驗證工具: 部署後,務必使用 Google 的 複合式搜尋結果測試 (Rich Results Test) 進行檢查。如果出現紅色的 Error,Google 就不會顯示特殊版位。
- 動態生成: 永遠不要手寫這些代碼。請要求後端工程師根據資料庫欄位自動生成 JSON-LD,確保庫存狀態 (InStock/OutOfStock) 與價格永遠與頁面顯示的一致。

前端開發者的惡夢:JavaScript SEO 與網頁渲染
如果你是使用 React、Vue 或 Angular 開發網站,你可能享受著極佳的使用者體驗 (UX),但你的 SEO 可能正處於危險之中。這是一個經典的技術矛盾:使用者喜歡流暢的動態網頁,但搜尋引擎偏愛靜態的 HTML。
Google 爬蟲本質上是一個「無頭瀏覽器」(Headless Browser)。雖然它現在已經具備執行 JavaScript 的能力,但這個過程既耗時又不穩定。如果你的網站完全依賴 客戶端渲染 (CSR),爬蟲第一次造訪時,看到的可能只是一個沒有內容的空殼 (<div id="app"></div>),因為 JS 檔案還沒執行完畢。
這就是為什麼很多現代網站明明內容豐富,在 Google 眼中卻是「空白頁面」。
用戶端渲染 (CSR) vs 伺服器端渲染 (SSR)
要解決這個問題,我們必須從 網頁渲染 (Page Rendering) 的機制下手:
瀏覽器下載一個空的 HTML 和一堆 JS 檔案,然後在用戶的電腦上「組裝」出畫面。
SEO 風險: 爬蟲抓取時 JS 可能還沒跑完,導致內容沒被收錄。Google 需要進行「第二波索引」,這會嚴重延遲排名更新的速度,甚至數週都不更新。
伺服器在後端就先把 HTML 組裝好,直接丟給瀏覽器。
SEO 優勢: 爬蟲一進來就看到完整的標題、文字與圖片,不需要執行 JS 也能讀懂內容。這是目前 技術 SEO 推薦的最佳實踐 (Best Practice)。
若無法全面改用 SSR(如 Next.js 或 Nuxt.js),你也可以考慮 動態渲染 (Dynamic Rendering):透過中介軟體 (Middleware) 偵測 User-Agent,如果是真人使用者就給 JS 版本以維持互動性,如果是 Googlebot 就給預先渲染好的靜態 HTML 快照。
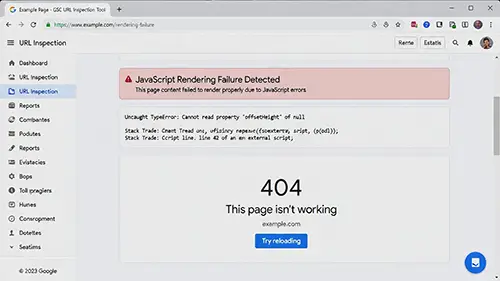
如何檢查 Google 是否「看見」了你的內容?
不要猜測,要測試。很多開發者以為「我按右鍵檢視原始碼有看到」就沒問題,這是不夠的。
請利用 Google Search Console 的 「網址審查 (URL Inspection)」 工具:
- 輸入你的網址,點擊「測試公開網址 (Test Live URL)」。
- 點擊 「查看檢索到的網頁 (View Crawled Page)」。
關鍵檢查:
- HTML 原始碼: 搜尋你的關鍵字或文章內容。如果沒找到,代表內容被 JS 擋住了。
- 螢幕截圖 (Screenshot): 切換到截圖分頁,看看 Google 抓到的畫面是否跟你看到的一樣。如果畫面是一片白,或缺少重要區塊,請立即聯絡工程團隊評估 SSR 或預渲染 (Prerendering) 解決方案。
進軍全球市場:Hreflang 多語系標籤設定
如果你經營的是跨境電商或多語系部落格,多語系 SEO (Multilingual SEO) 絕對是成敗關鍵。
試想一下,一位美國客戶搜尋你的品牌,結果點進去卻是全中文的頁面。他會做什麼?十之八九會直接按上一頁離開。這不僅損失了訂單,高跳出率還會告訴 Google:「這個頁面不適合這個關鍵字。」
Hreflang 標籤 就是用來解決這個問題的。它明確告訴 Google:「這個頁面是給講英文的美國人看的,那個頁面是給講中文的台灣人看的。」這能確保搜尋引擎將正確的語言版本推送給正確的地區用戶。
x-default 與語言代碼的常見錯誤
設定 Hreflang 最容易踩到的兩個地雷,這可能導致所有語系頁面都無法正確排名:
| 錯誤類型 | 說明 | 正確範例 |
|---|---|---|
| 語言代碼錯誤 | 很多開發者憑直覺寫 en-UK(錯誤)。正確寫法是 ISO 639-1 + ISO 3166-1 Alpha 2。寫錯代碼等於沒寫。 | en-GB (英國英語)en-US (美國英語) |
| 遺漏 x-default | 當使用者語言不在支援範圍內(如法國人),該顯示哪一頁?這是全球通用的預設入口。 | 指向英文版或語言選單首頁 |
雙向連結原則 (Reciprocal Links)
這是最常被遺忘的規則:如果 A 頁面指向 B 頁面,B 頁面也必須指回 A 頁面。
如果你的中文版指向英文版,但英文版沒有指回中文版,Google 會認為這是一個錯誤(或有人惡意劫持),並忽略這些 Hreflang 標記。請確保你的代碼在所有語系頁面上都是完整的閉環。
<!-- 正確範例 -->
<link rel="alternate" hreflang="en" href="https://example.com/en/" />
<link rel="alternate" hreflang="zh-TW" href="https://example.com/tw/" />
<link rel="alternate" hreflang="x-default" href="https://example.com/en/" />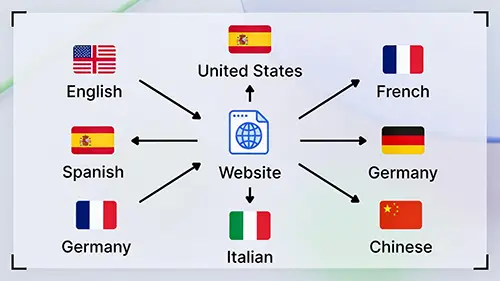
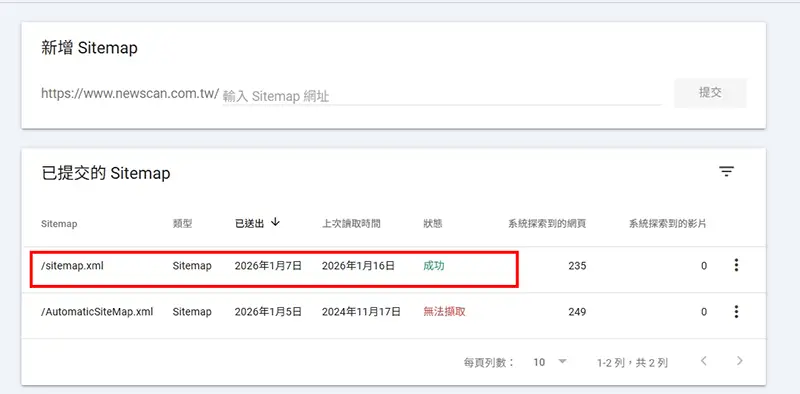
給爬蟲的導航地圖:XML Sitemap 深度優化
很多網站主以為安裝了 WordPress 外掛、生成了 sitemap.xml 就萬事大吉了。大錯特錯。一個充滿垃圾連結的 XML Sitemap (網站地圖),反而會降低 Google 對你網站的評價。
Sitemap 是你主動遞給 Google 的「邀請函」。既然是邀請函,你應該只把 最有價值、希望被收錄 的頁面放進去,而不是把雜物間(後台登入頁、測試頁、購物車頁)也寫在上面。
不只是提交:如何管理「索引優先級」與「更新頻率」
在 XML 檔案中,有兩個關鍵屬性常被忽略,善用它們可以提升抓取效率:
- Priority (優先級): 數值從 0.0 到 1.0。雖然 Google 表示這個標籤僅供參考,但設定合理的層級(首頁 1.0、主要分類 0.8、文章 0.6)有助於建立清晰的網站結構觀,讓爬蟲知道重點在哪。
- Lastmod (最後修改時間): 這才是最重要的標籤!當你更新舊文章時,務必透過 CMS 自動更新這個欄位。這會誘使爬蟲立刻回來重新抓取,讓你的內容更新更快反應在排名上。
排除垃圾頁面:Sitemap 不是垃圾桶
請定期檢查你的 Sitemap,確保裡面 沒有 以下東西:
- 301 重定向頁面: 只放最終目標網址,不要讓爬蟲多跑一趟冤枉路。
- 404 錯誤頁面: 這是叫爬蟲去撞牆,會嚴重浪費爬蟲預算 (Crawl Budget)。
- Noindex 頁面: 你既然都叫 Google 不要收錄了(Noindex),為什麼還要把連結放在地圖裡邀請它來?這會造成邏輯衝突 (Conflict)。
Pro Tip: 如果你的網站很大(超過 5 萬個網址),請務必將 Sitemap 分割成多個檔案(例如 sitemap-posts.xml, sitemap-products.xml),並建立一個 Sitemap Index 檔案來統整。這樣在 Search Console 中除錯時,才能快速找出是哪個區塊出了問題。
技術 SEO 常見問題 (FAQ)
這部分是為了搶佔 Google 的「使用者也有問 (People Also Ask)」版位所設計,請保持回答簡潔有力。
Canonical Tag 與 301 重定向有什麼不同?
結論: 兩者目的不同。
301 重定向會強制將使用者跳轉到新網址,適用於網址永久搬家;Canonical 則讓使用者留在原頁面,但告訴 Google 將權重算在另一個標準頁面上,適用於商品參數頁或保留舊內容供參考時。
為什麼我設定了 Schema 結構化資料,搜尋結果卻沒變化?
結論: Google 不保證一定會顯示複合式搜尋結果。
常見原因包括:程式碼有語法錯誤(請用 Rich Results Test 檢查)、內容與標記不符(例如標記了食譜但頁面是賣鍋具,被視為垃圾內容),或是網站整體的權威性 (Authority) 還不足以讓 Google 信任。
提交 Sitemap 後,多久會被 Google 收錄?
結論: 通常需要數天到數週不等,視網站權重而定。
提交 Sitemap 只是「邀請」。若想加速收錄,建議針對重要頁面使用 Search Console 的「網址審查」功能,手動點擊「要求建立索引 (Request Indexing)」插隊處理,通常能在 24 小時內見效。
技術 SEO (Technical SEO) 聽起來很艱澀,但它的邏輯其實很簡單:消除溝通障礙。
無論你的內容寫得再好,如果因為 JavaScript 渲染問題讓爬蟲看到白卷,或因為缺乏 Canonical 設定導致權重被稀釋,那都是枉然。今天我們討論的每一個標籤——從 JSON-LD 到 Hreflang——都是在幫你的網站鋪路,讓 Google 的爬蟲跑車能毫無阻礙地抵達終點。
現在,地基已經打穩。請回到你的網站後台,打開你的程式碼編輯器,開始這一場讓網站「脫胎換骨」的技術優化吧!
🎁 Bonus: 社交媒體分享文案
- 痛點直擊版: 「明明內容這麽好,為什麼 Google 就是不收錄????? 可能是你的 JavaScript 在搞鬼!這篇技術 SEO 指南教你如何讓爬蟲看懂你的網站,別再讓網站做白工。 #SEO #工程師 #行銷」
- 專業知識版: 「Canonical Tag 和 301 轉址分不清楚?小心你的網站權重被稀釋光光!一篇文搞懂技術 SEO 的核心地基,解決重複內容危機。???? [連結]」
- 數據成效版: 「想讓搜尋結果的點擊率提升 30% 嗎?秘密就在 JSON-LD 結構化資料。別只會寫文章,要學會搶版面!附完整代碼教學。???? #DigitalMarketing #TechnicalSEO」